TLDR: Backlash against the AIfication of all the things is good. Legislation around those issues is sorely needed. But we should be careful not to simply shift the balance of power among the already powerful. Whoever wins that war won't care any more about the commons that its predecessor.
A week or so ago I set up a forgejo1 instance to host my git repositories.
The main idea was to use it for the few private repos I have and ditch the old bitbucket account I've been using for those.2 I pondered the idea of moving all my stuff there and leave Github behind too, but that's trickier.
It's like social media. Everyone is on Github, so it's hard to go elsewhere for code you intend to be public. None of the stuff I have on there is of much interest, but still, what if someone stumbles upon it and feels like suggesting a fix or report an issue ? I don't want to open registration and manage random users on my private instance (nor to force people to create yet another account if they feel like contributing). But if I'm gonna pass up on the chance to get feedback, why even bother opening my source ?
I know there are cleaner, non-profit, FOSS and what-have-you alternatives for this. I'll explore them, but in the meantime, I figured I'd just leave the public things on Github. I can still change my mind about this later on.
Still, I moved my dotfile3 repo to my new forge because why the hell not.
Spot the Bot
I woke up friday morning, grabbed a cup of coffee and sat at the computer. I had published my last article on the previous evening, so, wondering if it had gotten some traffic, I glanced at my logs4 and was greeted with this:
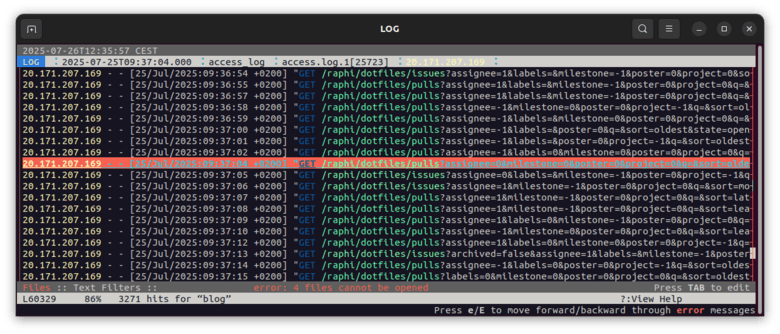
Some bot was crawling my config files as I watched. I could see each new request pop up, one every second. I could almost hear it go "Tick, Tick, Tick".
It was apparently going through the list of issues and pull requests for the repository... Of which there are none whatsoever. I guess the spider expects a different arborescence and got stuck in a loop.
Who the hell would care about this crap ? I looked up the IP and found it was owned by Microsoft.
So.
Microsoft owns Github, which gives them access to most of the open source code out there, which they use to feed their Copilot AI. Apparently that's not enough for them, so they go and crawl random forges hosted elsewhere. Sigh.
I banned the IP and moved on.5 Later during the day, I spotted the bot again, using a different IP (this one was trying to access some non-public pages and kept being redirected to the login page). I banned it too.
I'll give this to them: resources wise, one request a second is nothing. I read about LLM crawlers DDoSing small servers, which is not what's happening here. So at least they're not burning down this house as they steal the furniture. I haven't set up a robots.txt for the forgejo site, and I half wonder whether they'd respect it or not. Given that the IP has been reported as abusive, I have my doubts. And even if this bot does, many others don't.
This is a bit depressing.6 These crawlers are the reason why you can't access any site without having to demonstrate you're not a bot these days. On top of the adds and cookie banners, it's yet one more of those constant interuptions that make navigating the web infuriating.
I'll look into solutions to try and detect those bots and ban them automatically, but it pisses me off to even have to think about this for such a small website.
We're not talking about script kiddies or villainous hackers here. Those are perfectly legal and legitimate businesses that, non-content with having ruined everything they could on their own land, are now treating the rest of the web as their data mine. If you enjoyed technofeodalism, you'll love colonization 2.0.
Impact on self hosting
My ideal web is one where everyone would self host their stuff, and while I realize this is probably still unrealistic, real progress is being made on tools to allow less-technical people to manage it.
Dealing with misbehaving crawlers is yet another hurdle that many won't be able or want to deal with. And automated tools are bound to consume more resources.
Today, an old machine with 2Gb of RAM is more than enough to host a simple static site like this one (assuming you're not aiming for millions of daily views, of course). If everyone suddenly needs to protect themselves from unwanted bot traffic, the machines will need to get beefier, and recycling your ten years old laptop or getting a cheap Raspberry PI might not suffice anymore.
Infrastructure provider Cloudflare is now blocking those crawlers by default and proposing a pay-per-crawl fee to remunerate the scraped sites (assuming you use their service, of course). It sounds like a good idea on paper, but all I'm seeing is a giant red flag.
I don't really know anything about Cloudflare, but their wikipedia page claims they're fronting almost 20% of all websites already. Which is enormous. Whether or not the current direction can be trusted not to mess with things doesn't matter at this point: letting one company take up such a central position can only be bad news.
They have everything to gain from standing up against the AI bots, and the small web has everything to lose from relying (ie depending) on them for protection.
This leaves us self hosters to roll up our own protection, which, again, is an additional cost and barrier to entry (both monetary and technical). So that sucks.
I'm no sys admin, so I don't really know what's available. I'll investigates WAFs and see if something interesting comes up. Anubis seems to be popular and efficient, but I'd really like to avoid anything that affects regular readers.7
Copyright won't save us

A lot has already been said about the problems those AI crawlers pose regarding intellectual property. I happen to think that the current copyright system is an abomination that should be revised from the ground up, and I have little hope the conversation will even entertain the idea of actually fixing it, so I'm wary of this line of defense.
About a month ago, Disney and Universal sued Midjourney over this. I haven't followed the reactions, but I don't think we should cheer them on. I certainly don't mind if Midjourney gets knocked down a peg, but seeing those giant leeches cry over their IP when they already own everything makes me sick.
They're not out to champion the cause of the smaller creators who actually suffer from this situation. They're only in it to maximize their own profit, and should some legislation come out of this, it will only reinforce their own power. Independant artists might benefit in the short term, but the best they can hope for is maintaining the status-quo.
The AI companies' argument that their unsolicited use of material to feed their machines falls under Fair Use is bullshit. But Fair Use is still an important aspect of copyright law, that right owners happily disregard when it suits them, usually with complete impunity. Weakening it further can't be good in the long run.
It's tough. There's no good guy in this story. Even though the system sucks, it may help prevent or slow down the pillaging of actual, valuable work. But this system is already used by the bigger players to shut down criticism and enforce censorship. As we drift ever closer to an authoritarian dystopia, I'm not sure we stand to gain from strenghtening property rights even further.
In the end, it's a battle between giant corporations. Whoever wins will just take all the spoils. Our interest might align somewhat with Disney's right now, but let's not fool ourselves into thinking they're fighting on our behalf, and let them get away with new ways to control ever more media.
Allright. This started as a quick little rant and grew some legs as it went on. A lot of what I said is based on gut feeling and pre-existing opinions. I don't think anything's blatantly false, but I haven't truly researched most of my points and some of them may be a bit hazy. I'd better stop here and keep to first impressions rather than try to go more in depth and risk making a fool of myself.
Also, talking about business models, policy and all that grown up crap in English is definitely not my forte. I hope I managed to get my points accross without sounding too simplistic.
At any rate, I found this EFF article while looking for links that sums up the whole AI crawlers situation much better than I could.
So long. I promise the next article won't be about tech.
-
A fork of gitea that claims to be "more free" than its upstream. ↩
-
Private repos used to be a paying feature on Github. Bitbucket had a different pricing strategy, so I went there for those.
Ten years later I just get annoyed at managing two different accounts and I'd rather keep that code to myself anyway. ↩
-
Linux systems config files tend to be simple hidden files scattered in your home directory. Under Unix, hidden files are indicated by a dot prefix to the file name, like
.bashrc. Hence the "dotfiles" nickname.It's common practice to store those in a Git repo so that it's easy to retrieve when you set up a new machine and keep a log of your changes (useful when you can't remember why in hell you changed some random bit years after the fact). ↩
-
I haven't setup analytics for this site. Still looking for a simple enough and self hosted solution, but that's pretty low on my todo list. So for now, I just look at the server logs when the itch to see what's going on start scratching. ↩
-
Ain't no better way to start the day than reading firewall docs. ↩
-
And ridiculous, too. My dotfiles repo is still on Github, so they're scraping code they already have. Also, it's freaking config. Personal tweaks tailored to the way I like to use my tools. This has to be the least interesting thing to feed an LLM with. ↩
-
It's much better than a regular CAPTCHA, but still. The small delay it incurs is exacly the kind of small annoyances that add up fast and end up ruining the whole experience of surfing the web for me. ↩